Intelligent proxy caching based on the
Abstract
The general research of this work is to make proxy caching more efficient in the GroupWare environment where the web pages being fetched by some group members, or potentially to being fetched by some group members may be interest for other group members. The specific problem that our research focuses at is how to do efficient prefetching and caching in conditions when each already fetched web presentation includes pointers to potential follow-up presentation. Existing approaches base their prefetching and caching on the information how frequently some presentation is used, volume of presentation and time to being fetched, who is who in GroupWare hierarchy, what are the keywords involved in currently opened document or hints from the system administrators. Our approach utilizes temporal locality; under the term temporal local web presentations we imply those which are found in the list of the replaced from the cache, characterized with the relative impact factor (i.e. how often were they read when they were in the cache). We demonstrate that our approach is better then existing ones with doing following:
Introduction
Growth of popularity of World Wide Web resulted in frequent redundant accesses to popular Internet resources. Caching reduces accesses moving the most popular objects closer to the user. The main goal of the caching is to do following:
Since caching storage space is limited, some objects are removed. Removing policy selects what will be kept in cache, and what will be removed, optimizing one or more previously mentioned goals. It is important to chose right removing policy to achieve maximum cache performance. Optimization of one goal may impact others. Prefetching minimizes the time that end users wait for an object to load.
Problem statement
There are few parameters which are of interest in caching: volume of an object, time that it takes to fetch an object (to the proxy server and from the server to the end user), and probability of repeating access to the same object. Volume of an object is known before fetching. Times can be estimated knowing average transfer rate over connections from proxy to server and from end user to proxy. Estimation of probability of the repeating access to the same object requires to be acquainted with nature of requests. There is no exact way to do requested. On the other hand it is very important to estimate probability which will be closer to the real situation to make all calculations worth. The field of this research is estimation of probability, which will lead to achieving better performance of caching and prefetching.
Existing solutions
Removal polices, such as the first in, first out (FIFO), least recently used (LRU), least frequently used (LFU), removal policy proposed by Pitkow/Recker[PR94] base their predictions of future accesses to objects using frequency and/or recency rates of prior object accesses. As proposed in [WAS96] removing policy can be viewed as a sorting problem and objects are sorted and putted in a queue for removal. To achieve better performance, the second key can be added. Cost for fetching and storing objects is usually taken as the second key. It is implemented in proxy caching that estimates page load delay [WA97], algorithms explained, analyzed and referenced in [Par96] and others.
Proposed algorithms do not predict when will occur next access to some object. Some algorithms suppose that time till next equals previous delay between accesses. Since time access patterns can be more complex than this one, some advance in this direction could be done.
Proposed solution
Predicting the time of the next access
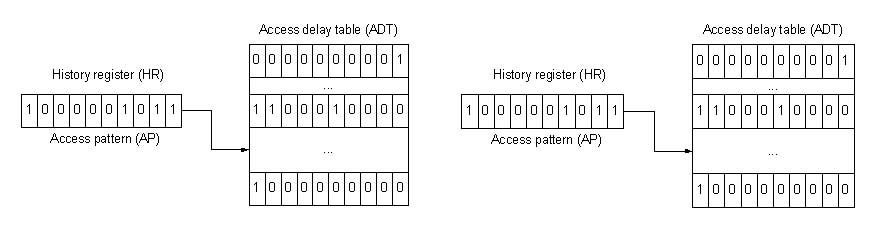
Existing predicting mechanisms do not predict the time of the next access. They are usually based on assumption that more valuable are those objects that are in trend (LRU) or that are of greater need (LFU) or that are required recently (FIFO). By predicting the time of next access, more sophisticated heuristics could be employed. Proposed predicting mechanism should have enough information to use more than one possible characteristic in prediction. Thus, delays between previous n accesses are being tracked in the history register (HR). Each object has it’s own history register which addresses one entry in access delay table (ADT) that contains all possible delays for this state. Some heuristics can chose next most possible delay (e.g., the worst case, or first larger then time passed since last access). Parameters that characterize work of the algorithm are:
These parameters will be examined during simulation.
Figure 1 Example: HR points to appropriate entry in ADT. All predictions are made according to delays found for that entry. When different delay found for this object it is recorded in the entry and HR is directed to other entry
The example is shown on the Figure 1. Each D t units of time 0 or 1 is shifted in from the left according to access to the object. In HR it is found that all possible delays are less or equal one or two D t. So, prediction is based on this information. When 6D t delay found in the pattern, addressed entrance in ADT is modified and HR directed to new entrance. All objects that address the previously addressed entrance in ADT, could have new future. If found that there were no accesses longer than 2D t it is supposed that next access will occur after 6D t.
Since this function returns exact time of next access, more quality in caching is expected. This function will be referenced as TDT (time delay tracking).
Conditions and assumption of the research
Approximation of this algorithm will track previous n delays between accesses (classified in 10 categories - states). Analyzing traces, probabilities of transiting from state to state will be found. The next state will be predicted as state found in file’s history with the highest probability of being the next one.
If some improvement is found, the proposed algorithm will be simulated.
Theoretical analysis
Analyzing temporal locality in the Web caching
Temporal locality on the Web is caused by repeated access of one or more user to the single object. If repeated access is located in short time interval it is supposed that next access will occur in near future. If some kind of rule could be found in access pattern, more qualitative prediction could be performed [PR94] . Knowing the time of next access can be used in numerous ways. Objects that have expiration time smaller than time of next access can be purged to free space for incoming documents. Objects that will never be accessed also can be purged. Object that have known but distant access time can be purged, but prefetched before needed. The question is: is it reasonable to expect some periodical behavior of accesses?
Examined traces are obtained from NLANR (National Laboratory for Applied Network Research) with a grant from the National Science Foundation (grants NCR-9616602 and NCR-9521745).
They are collected during 4 days. The time is classified in 10 categories. Each category has 10% of all requests made during that period. Table 1 presents those intervals.
|
% req. |
10 |
20 |
30 |
40 |
50 |
60 |
70 |
80 |
90 |
100 |
|
seconds |
32 |
195 |
1005 |
3116 |
7910 |
17463 |
34918 |
66842 |
116272 |
343966 |
|
% time |
0,009 |
0,05 |
0,2 |
0,9 |
2 |
5 |
10 |
19 |
34 |
100 |
The idea is to see the relation between previous and next delay. It is assumed that the state is assigned to the file according to class of previous delay. Next state is class of a next delay. Figure 2 presents the probability of transiting from current state to another one.
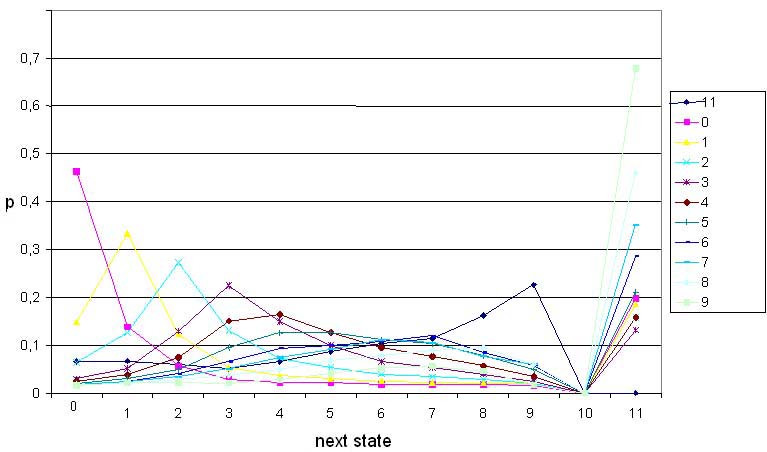
Figure 2 The probability of transiting from current to another state. State 10 is never reached. State 11 presents infidelity
There is high probability that the next state will be the same as previous. Also, there is high probability that the file will not be accessed (state 11).
The Figure 3 shows the probability that the next state is one of previous all, 10, 9...1 states.
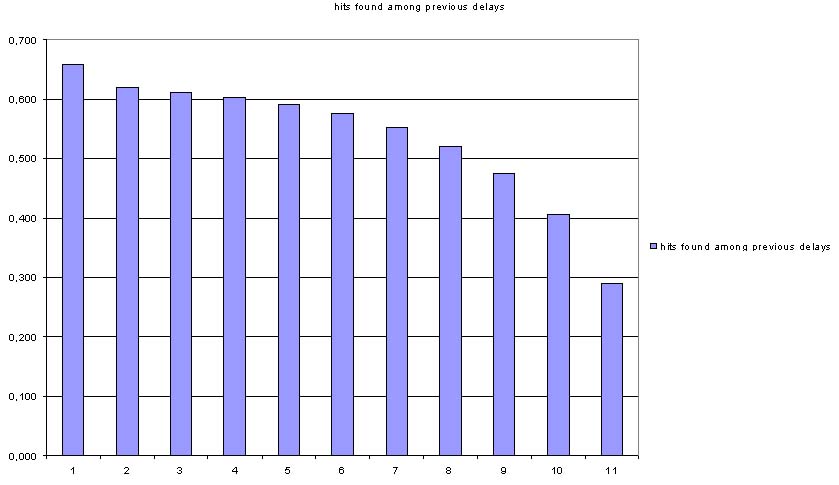
Figure 3 The probability of guessing next access based on delays between previous accesses.
This shows that there can be found some rule for predicting next state.
Simulation analysis
Simulation will compare the hit rate and weighted (byte) hit rate of proposed algorithm with following ones:
All caches have the same storage space. Accuracy of predicting next state will be also measured.
Results
Maximum delay between repeated request: 343966 seconds
TODO!
Implementational analysis
Since work is in progress we have no implementational analysis.
Conclusion
Results of the experiment have to show benefits of using proposed algorithms. Second, it is important to find conditions under which proposed algorithms improve existing situation. Also it is important to find appropriate parameters used in prediction (e.g., window and pane width, weighting time delays, …).
References
[PR94] James E. Pitkow and Margeret M. Recker. A Simple Yet Robust Caching Algorithm Based on Dynamic Access Patterns. In Proceedings of the Second International Conference on the World Wide Web, Chicago, 1994. URL: http://www.ncsa.uiuc.edu/SDG/IT94/Proceedings/DDay/pitkow/caching.html.
[KLM97] Thomas M. Kroeger Darrell D. E. Long Jeffrey C. Mogul. Exploring the Bounds of Web Latency Reduction from Caching and Prefetching URL:
[WAS96] Stephen Williams, Marc Abrams, Charles R. Standridge, Ghaleb Abdulla, Edward A. Fox. Removal Policies in Network Caches for World-Wide Web Documents.
[AW] M. F. Arlitt and C. L. Williamson. Web server workload characterization: The search for invariants. In Proc. SIGMETRICS, Philadelphia, PA, Apr. 1996. ACM.
[WA97] Roland P. Wooster and Marc Abrams, "Proxy Caching that Estimates Page Load Delays" , WWW6, April 1997 URL: http://www.cs.vt.edu/~chitra/docs/www6r/
[Par96] Tomas Partl. A comparison of WWW caching algorithm efficiency. In ICM Workshop on Web Caching, Warsaw, Poland, 1996. URL: http://w3cache.icm.edu.pl/workshop/
[BOLO96] Jean-Chrysostome Bolot, Philipp Hoschka, "Performance Engineering of the World Wide Web," WWW Journal 1, (3), 185-195, Summer 1996.URL: http://www.w3.org/pub/WWW/Journal/3/s3.bolot.html.
[RF98] Mike Reddy and Graham P. Fletcher. Intelligent web caching using document life histories: A comparison with existing cache management techniques. In Third International WWW Caching Workshop, Manchester, England, June 1998.URL: http://wwwcache.ja.net/events/workshop/
[BDR97] Gaurav Banga, Fred Douglis, and Michael Rabinovich.Optimistic Deltas for WWW Latency Reduction. In Proceedings of the USENIX Technical Conference,1997
[NLN98] Nicolas Niclausse, Zhen Liu, and Philippe Nain. A new and efficient caching policy for the world wide web. In Workshop on Internet Server Performance (WISP'98), Madison, WI, June 1998URL: http://www.cs.wisc.edu/~cao/WISP98.html
[SSV98] Junho Shim, Peter Scheuermann, and Radek Vingralek. A Unified Algorithm for Cache Raplacement and Consistency in Web Proxy Servers. In Proceedings of the Workshop on the Web and Data Bases (WebDB98), 1998. URL: http://epsilon.eecs.nwu.edu/~shimjh/publication/webdb98.ps
[RV98] Luigi Rizzo and Lorenzo Vicisano. Replacement policies for a proxy cache. Research Note RN/98/13, Department of Computer Science, University College London,1998. URL: http://www.iet.unipi.it/~luigi/research.html
[BC95] Azer Bestavros and Carlos Cunha. A Prefetching Protocol Using Client Speculation for the WWW. Technical Report TR-95-011, Boston University, CS Dept, Boston, MA, April 1995. URL:http://www.cs.bu.edu/faculty/best/res/papers/Home.html
[BC96] Azer Bestavros and Carlos Cunha.Server-initiated Document Dissemination for the WWW. IEEE Data Engineering Bulletin, 19(3):3-11, September 1996. URL: http://www.cs.bu.edu/faculty/best/res/papers/Home.html
[CB98] Mark Crovella and Paul Barford.The Network Effects of Prefetching. In Proceedings of IEEE Infocom '98, San Francisco, CA, 1998.URL: http://cs-www.bu.edu/faculty/crovella/paper-archive/infocom98.ps
[CY97] Ken-ichi Chinen and Suguru Yamaguchi. An interactive prefetching proxy server for improvement of WWW latency. In Proceedings of the Seventh Annual Conference of the Internet Society (INET'97), Kuala Lumpur, June 1997. URL: http://www.isoc.org/INET97/
[Pad95] Venkata N. Padmanabhan. Improving world wide web latency. Technical Report UCB/CSD-95-875, UC Berkeley, May 1995. URL:
[BC96] Azer Bestavros and Carlos Cunha.Server-initiated Document Dissemination for the WWW. IEEE Data Engineering Bulletin, 19(3):3-11,September 1996. URL:
[Bes95c] Azer Bestavros.Using Speculation to Reduce Server Load and Service Time on the WWW. In Proceedings of CIKM'95: The Fourth ACMInternational Conference on Information and Knowledge Management, Baltimore, MD, November 1995.
[CFKL95] Pei Cao, Edward W. Felten, Anna Karlin, and Kai Li.A Study of Integrated Prefetching and Caching Strategies. In Proceedings of the ACM SIGMETRICS Conference on Measurement and Modeling of Computer Systems, May 1995. URL:
[FCJ98] Li Fan, Pei Cao, and Quinn Jacobson. Web Prefetching Between Low-Bandwidth Clients and Proxies: Potential and Performance. This is anextended version of Technical Report 1372, Computer Science Dept., Univ. of Wisconsin-Madison, October 1998. URL:
[MC98] Evangelos P. Markatos and Catherine E. Chronaki. A top-10 approach for prefetching the web. In Proceedings of the Eighth Annual Conference of the Internet Society(INET'98), Geneva, Switzerland, July 1998.
[Mog96] Jeffrey C. Mogul. Hinted caching in the web. In Proceedings of the Seventh ACM SIGOPS European Workshop, Connemara, Ireland, September 1996. URL: http://mosquitonet.stanford.edu/sigops96/
[TB97] Sau Loon Tong and Vaduvur Bharghavan. Alleviating the Latency and Bandwidth Problems in WWW Browsing. In Proceedings of the USENIX Symposium on Internet Technologies and Systems (USITS '97), December 1997.
[Neb97] Masaaki NABESHIMA The Japan Cache Project: An Experiment on Domain Cache